Bak kulissene hos Juke KI
Enonic bygger smartere verktøy med praktisk KI. Se de tekniske detaljene under panseret på vår nye KI-agent Juke.
Written by Vegard Ottervig on
På en nylig Enonic-meetup inntok Mikita, programvareutvikler hos Enonic, scenen for å forklare hvordan teamet bygde Juke KI – Enonics chatbaserte, innholdsbevisste KI-assistent. Juke er allerede tilgjengelig for betalende kunder og er aktivt i ferd med å bli integrert i Enonic-økosystemet.
Men det som skiller den ut er ikke bare grensesnittet – det er ingeniørkunsten og erfaringene under panseret.
Se presentasjonen (på engelsk):
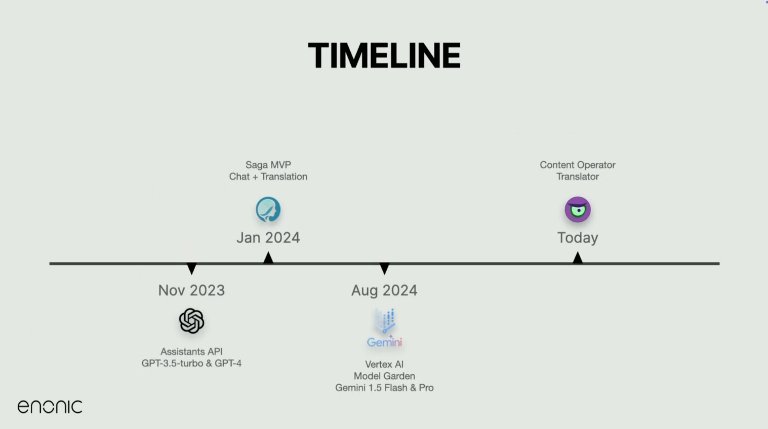
Fra MVP til modulær agent
Reisen startet sent i 2023, rett etter at OpenAI introduserte sitt Assistants API. Denne lanseringen gjorde det mulig å administrere historikk og samtaleflyt mer effektivt, og i løpet av en uke hadde Enonic-teamet kokt opp en prototype.
MVP-en fikk navnet Saga, og kombinerte grunnleggende chat- og oversettelsesfunksjoner i en enkel applikasjon. Etter hvert som kompleksiteten økte, delte teamet den inn i to dedikerte tjenester: én for innholdsinteraksjon og én for teksttransformasjon – og dannet til slutt grunnlaget for Juke.
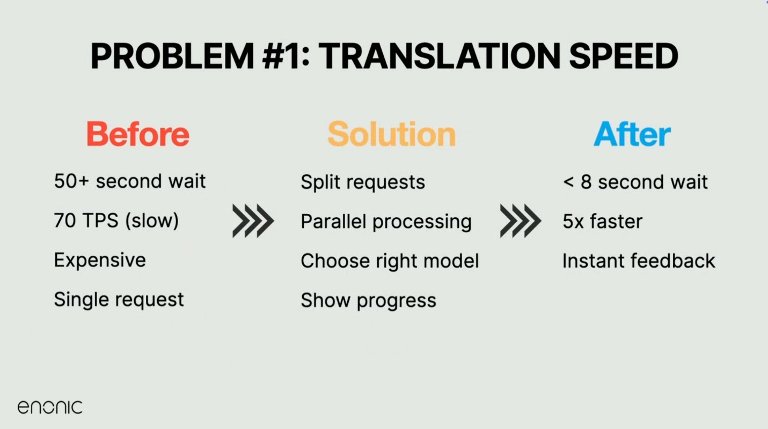
Få oversettelsen riktig: Ytelse først
En av de første store tekniske utfordringene Enonic taklet var oversettelseshastigheten. Store blokker med innhold – noen ganger flere A4-sider – tok over 50 sekunder å behandle. Det var for tregt til å være nyttig.
Løsningen? Å dele oversettelsesoppgaver etter felt og behandle dem parallelt med nøye throttling per bruker og per plattform. Kombinert med en overgang til raskere modeller som Gemini 1.5 og 2.0 Flash, reduserte denne tilnærmingen oversettelsestidene dramatisk – fra nesten et minutt til under fem sekunder for store inndata.
Disse endringene forbedret ikke bare ytelsen, men muliggjorde også fremdriftsindikatorer, som ga brukerne tilbakemelding i sanntid i stedet for blanke ventetider. Hovedlærdommen: Ikke bare bruk den kraftigste modellen – bruk den riktige modellen for oppgaven, og finjuster den godt.
Prompting: Mer kunst enn vitenskap
Mikita gikk gjennom noen av de uventede atferdene de opplevde da de jobbet med KI-prompter. Selv tydelig skrevne instruksjoner ble noen ganger ignorert eller misforstått av modellen.
For eksempel, når modellen ble bedt om å returnere markdown-formatert utdata, returnerte den ren tekst. Eller når JSON ble forespurt, pakket den noen ganger resultatet inn i markdown-formatering, eller enda verre, leverte kreative, men ubrukelige formateringsstrukturer.
For å løse dette raffinerte teamet sin prompting-tilnærming ved eksplisitt å definere forventede responstyper, forbedre eksempler og bruke robust logikk for resultathåndtering.
En av de viktigste lærdommene? Forvent alltid det uventede med generativ KI – og bygg sikkerhetsventiler for saker i grenseland. Det som fungerer for en versjon av en modell, kan brytes i den neste.
Løs komplekse oppgaver med flertrinnsbehandling
Opprinnelig prøvde Juke å håndtere analyse og innholdsgenerering i én enkelt KI-samtale, men denne tilnærmingen viste seg å være for skjør. Så teamet delte prosessen i to: først, et raskt og fokusert analysetrinn, deretter en mer kreativ genereringsfase.
Analysefasen bryter ned brukerinndata til oppgavedefinisjoner per felt – hvor mange varianter som skal genereres, hvilken stil eller tone som skal brukes, og hvilket språk som forventes. Det andre trinnet, ved hjelp av en mer kapabel modell, genererer det faktiske innholdet ved hjelp av instruksjonssettet og et definert skjema.
Denne endringen gjorde utdataene mer nøyaktige, pålitelige og konsistente – selv på tvers av store eller komplekse innholdsdeler.
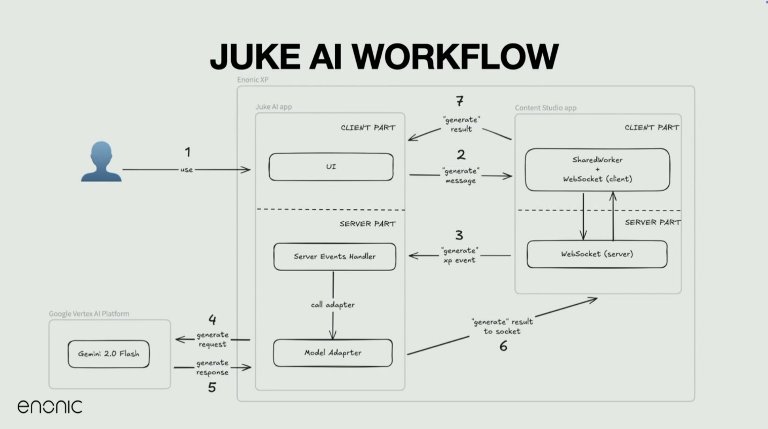
Hvordan Juke integreres med Enonic
Fra et arkitekturperspektiv kjører hver Juke-applikasjon som en frittstående XP-app, og kommuniserer via serverhendelser og nettleserhendelser.
Content Studio injiserer deler av Juke-koden i sin DOM og lytter etter KI-genererte resultater, noe som gjør det mulig å samhandle direkte med innholdsfelt.
Brukere kan klikke på en knapp for å forenkle tekst eller generere en oversettelse, som utløser en rekke bakgrunnshendelser. Disse inkluderer websockets, delte arbeidere og serverhendelser – som strømmer tilbake til brukergrensesnittet.
Juke-apper bruker et modelladapterlag for å samhandle med KI-modeller som Gemini, og pakker inn logikk for samtalehistorikk, rate-begrensning og innholdsformatering. Resultatet er en sømløs, toveis kommunikasjonsflyt mellom redaktørgrensesnittet og KI-modellene.
Erfaringer og beste praksis
Mikita avsluttet med flere viktige lærdommer for alle som bygger eller integrerer KI:
- Del komplekse oppgaver inn i trinn i stedet for å stole på én gigantisk prompt.
- Bruk mindre modeller når det er hensiktsmessig – de er raskere, billigere og ofte like gode for målrettede oppgaver som oversettelse.
- Forvent inkonsekvens. Selv strukturert utdata som JSON kan komme i uforutsigbare former.
- Prompter bør være klare, spesifikke og minimale. Overbelastede prompter forvirrer modellene og fører til uberegnelig oppførsel.
- Gi umiddelbar tilbakemelding i brukergrensesnittet der det er mulig. Brukere stoler mer på KI når de ser den "tenke".
- Revider prompter kontinuerlig. Det som fungerte forrige måned, kan brytes med en modelloppdatering. Test og tilpass alltid.
Hva er det neste for Juke?
Juke KI støtter allerede egendefinerte ordbøker, stilguider og instruksjoner på prosjektnivå – avgjørende for selskaper med domenespesifikt språk eller merkevarekrav. Fremtidige versjoner vil gjøre det enklere å bruke disse konfigurasjonene på hele nettstedet, og rulles sannsynligvis ut sammen med Content Studio 6.
Enonic bruker for tiden Gemini 2.0 i produksjon, men planlegger å gå over til Gemini 2.5 når den forlater beta. Forbedringene er bemerkelsesverdige, spesielt innen resonnering og strukturerte genereringsoppgaver.
Da en deltaker spurte om å skreddersy KI-atferd etter brukerkontekst – for eksempel å skrive i forskjellige toneleier avhengig av innholdsområdet – bekreftet Mikita at det allerede er mulig, og ytterligere forbedringer er under utvikling for å støtte enda mer finkornet kontroll.
Vil du prøve Juke i ditt eget miljø eller lære mer om teknologien bak den? Ta kontakt med Enonic-teamet i dag.