Hvordan man bygger en søkeløsning med Explorer 4.0
Dykk ned i den nyeste versjonen av vårt enterprise-søkeløsning Explorer.
Written by Thomas Sigdestad on

Dykk ned i den nyeste versjonen av vårt enterprise-søkeløsning Explorer.
Written by Thomas Sigdestad on
Vi holdt nylig et Meetup hvor vår Senior Software Engineer Christian Westgaard demonstrerte hvordan man bygger en søkeløsning på vår enterprise-søkeplattform Explorer, som nå er i sin fjerde iterasjon.
I dette tilhørende blogginnlegget dykker vi ned i en praktisk anvendelse av Enonic og Explorer-verktøyet, og viser hvordan man effektivt administrerer og søker i data, med et spesielt fokus på et bildatasett fra Finn.no.
Se videoen:

Explorer har to hovedfunksjoner: å indeksere data på en strukturert måte for å muliggjøre avanserte søk. I denne demonstrasjonen vil vi hovedsakelig bruke Explorer til å utføre en nyttig oppgave: å opprette en søkbar database med biler.
Prosessen starter med å sette opp Enonic. Etter å ha opprettet en sandkasse og installert Explorer direkte fra Market, er vi klare til å bruke dette kraftige verktøyet.
Det første trinnet innebærer å definere hvilken data vi skal lagre og søke i. I dette tilfellet er det biler. Christian har opprettet en dokumenttype på norsk, som tillater automatisk feltgenerering, noe vi vil utforske senere.
Samtidig opprettes en samling for å lagre dataene, i hovedsak et standard XP-repositorium kalt “Biler”. Denne oppsettet er avgjørende for dataindekserings- og hentingsprosessen.
Det finnes to metoder for å fylle data: bygge en collector innenfor Enonic eller bruke et eksternt skript for å pushe data via et REST-API. For denne demoen har vi valgt sistnevnte, som krever å sette opp en API-nøkkel for sikkerhet.
REST-API-endepunktet er allsidig og støtter ulike operasjoner som CRUD for både bulk- og enkeltoppføringer.
Christian utviklet en crawler ved hjelp av Node-moduler, spesielt ‘Surgeon’, som parser HTML til DOM-strukturer og tillater CSS-valg innenfor disse strukturene. Denne crawleren henter bildata fra Finn.no, og fanger detaljert informasjon som lenker, bilattributter og mer.
For å kjøre denne crawleren brukte Christian ‘bun’, et prosjekt som tar sikte på å løse vanlige JavaScript-problemer, og fungerer som et raskere alternativ til Node og NPM. Når skriptet kjører, henter det bildata fra Finn.no, som deretter reflekteres i Explorers voksende bilsamling.
Explorer genererer automatisk felter i dokumenttypen basert på de inntatte dataene, og kategoriserer dem som strenger, tall, datoer osv. Denne funksjonen er essensiell for å vise informasjon på en nettside og søke i dataene.
For å søke i dataene opprettes et grensesnitt i Explorer. Dette grensesnittet lar oss booste visse felter, noe som øker deres vekt i søkeresultatene. Ved hjelp av GraphQL kan vi utføre søk, aggregere og filtrere resultater basert på ulike parametere som bilmodeller, alder og drivstofftype.
Søkeklienten, bygget med en enkel create-react-app, benytter GraphQL-API for funksjonaliteten. Dette API-et støtter funksjoner som highlighting, filtre og aggregeringer, som muliggjør raffinerte søk basert på spesifikke kriterier.
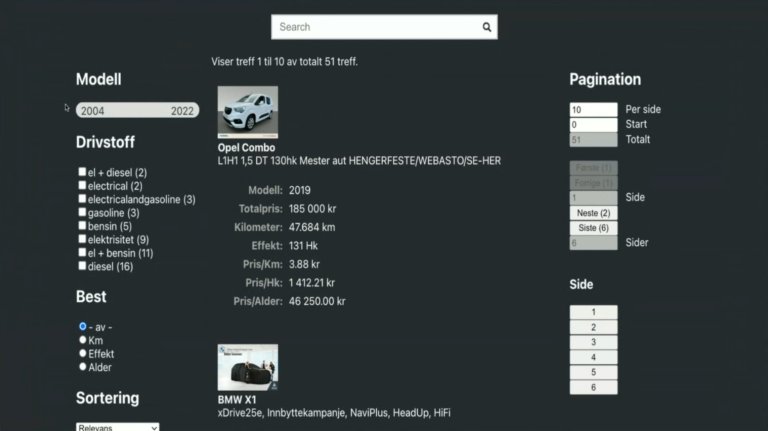
Etter å ha lagt til grensesnittet i API-nøkkelen, kan vi ytterligere raffinere søkefunksjonaliteten. For eksempel kan vi sortere biler basert på pris per kilometer eller filtrere etter drivstofftype. Aggregeringer brukes til å bestemme aldersspennet på bilene og tilgjengelige drivstofftyper.
Søkeklienten inkluderer også paginering, ved hjelp av GraphQL for å spesifisere antall resultater per side og startpunktet for hver side. Den kan også brukes til å opprette en “Last mer”-knapp.
Til slutt støtter klienten avansert filtrering. Disse funksjonene legger til et lag av bekvemmelighet og effektivitet til brukeropplevelsen.
Explorer utvider søkemulighetene til Enonic-plattformen utover dens interne data, og muliggjør høyst tilpassbare søk. Denne tilpasningsevnen er spesielt gunstig for aggregering og søk i ulike datatyper, som demonstrert i eksempelet Helsebiblioteket, som aggregerer innhold fra 50–70 forskjellige kilder.
Konklusjonen er at integrasjonen av Enonic med Explorer tilbyr en robust løsning for administrasjon og søk i forskjellige datasett. Enten det er for å aggregere data fra flere kilder eller forbedre søkefunksjonaliteten, viser denne kombinasjonen seg å være et kraftig verktøy i databehandling og -henting.
Utforsk Explorer på Enonic Market.
Få enda mer innsikt 🤓

