Behind the Scenes of Juke AI
Enonic is building smarter tools with practical AI. See the technical details behind the curtains of our new AI agent Juke.
Written by Vegard Ottervig on
At the latest Enonic Meetup, Mikita, Software Engineer at Enonic, took the stage to explain how the team built Juke AI—Enonic’s conversational, content-aware AI assistant. Juke is already available to paying customers and is actively being integrated into the Enonic ecosystem.
But what sets it apart isn't just the interface—it’s the engineering and lessons learned under the hood.
See the presentation:
From MVP to Modular Agent
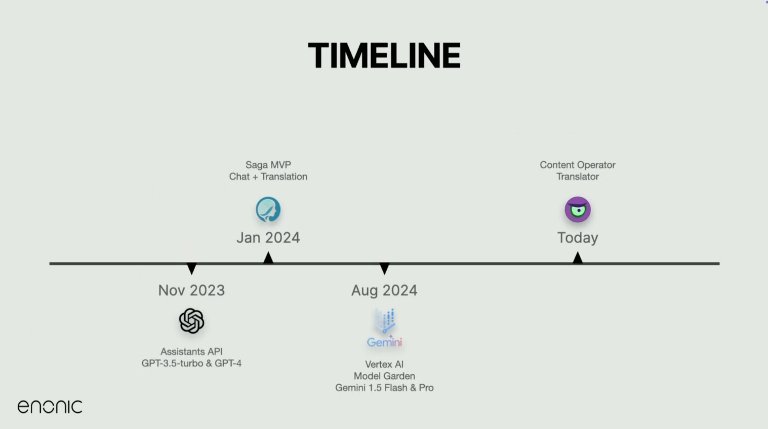
The journey began in late 2023, just after OpenAI introduced its Assistants API. That release made it possible to manage history and conversation flow more effectively, and within a week, the Enonic team had spun up a prototype.
Dubbed Saga, the MVP combined basic chat and translation capabilities within a single application. However, as complexity grew, the team split it into two dedicated services: one for content interaction and one for text transformation—ultimately forming the foundation for Juke AI.
Getting Translation Right: Performance First
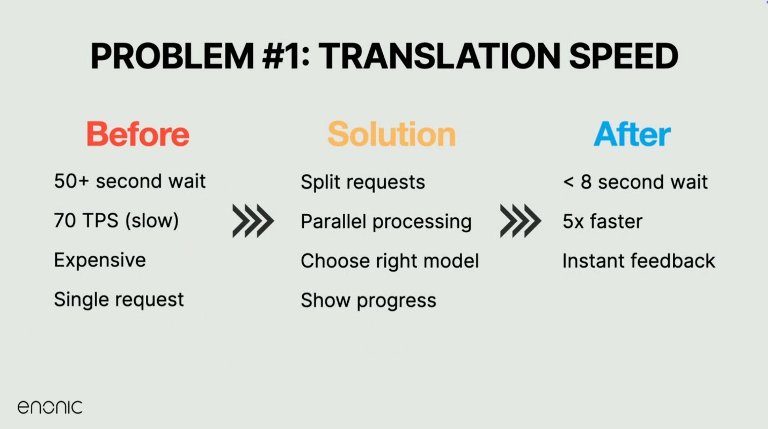
One of the first major technical challenges Enonic tackled was the speed of translation. Large blocks of content—sometimes multiple A4 pages—were taking over 50 seconds to process. That was too slow to be useful.
The solution? Splitting translation tasks by field and processing them in parallel with careful throttling per user and per platform. Combined with a switch to faster models like Gemini 1.5 and 2.0 Flash, this approach brought translation times down dramatically—from nearly a minute to under five seconds for large inputs.
These changes not only improved performance but allowed for progress indicators, giving users real-time feedback instead of blank waits. The key lesson: don’t just use the most powerful model—use the right model for the task, and tune it well.
Prompting: More Art Than Science
Mikita walked the audience through some of the unexpected behaviors they encountered when working with AI prompts. Even clearly written instructions were sometimes ignored or misunderstood by the model.
For example, when asked to return a markdown-formatted output, the model returned plain text—or when JSON was requested, it sometimes wrapped the result in markdown formatting, or worse, delivered creative-but-useless formatting structures.
To address this, the team refined their prompting approach by explicitly defining expected response types, improving examples, and using robust result handling logic.
One of the big takeaways? Always expect the unexpected with generative AI—and build fallbacks for edge cases. What works for one version of a model may break in the next.
Solving Complex Tasks with Multi-Step Processing
Initially, Juke was trying to handle analysis and content generation in a single AI call, but this approach proved too brittle. So the team split the process into two: first, a fast and focused analysis step, then a more creative generation phase.
The analysis phase breaks down user input into task definitions per field—how many variants to generate, what style or tone to use, and what language is expected. The second step, using a more capable model, generates the actual content using that instruction set and a defined schema.
This change made outputs more accurate, reliable, and consistent—even across large or complex pieces of content.
How Juke Integrates with Enonic XP
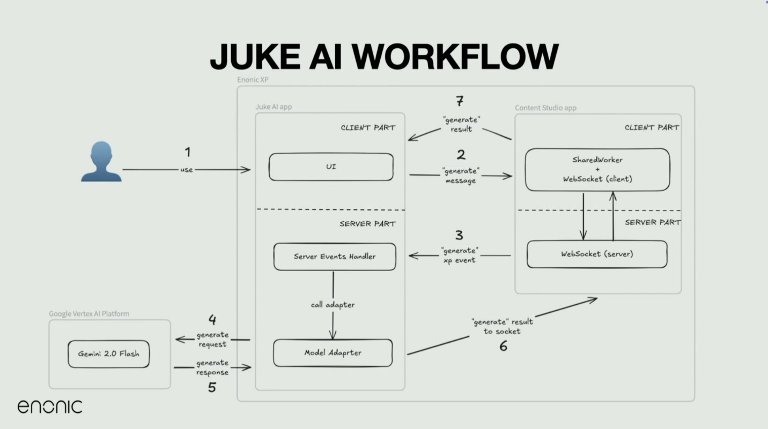
From an architecture perspective, each Juke application runs as a standalone XP app, communicating via server events and browser events.
Content Studio injects part of the Juke code into its DOM and listens for AI-generated results, making it possible to interact with content fields directly.
Users might click a button to simplify text or generate a translation, which triggers a series of background events. These include websockets, shared workers, and server events—that flow back into the UI.
Juke apps use a model adapter layer to interact with AI models like Gemini, wrapping logic for conversation history, rate limiting, and content formatting. The result is a seamless, two-way communication flow between the editor interface and the AI models.
Lessons Learned and Best Practices
Mikita wrapped up with several key lessons for anyone building or integrating AI:
- Split complex tasks into steps rather than relying on one giant prompt.
- Use smaller models when appropriate—they’re faster, cheaper, and often just as good for targeted tasks like translation.
- Expect inconsistency. Even structured output like JSON can come in unpredictable forms.
- Prompts should be clear, specific, and minimal. Overloaded prompts confuse models and lead to erratic behavior.
- Provide instant feedback in the UI wherever possible. Users trust AI more when they see it “thinking.”
- Continuously revise prompts. What worked last month might break with a model update. Always test and adapt.
What’s Next for Juke?
Juke AI already supports custom dictionaries, style guides, and project-level instructions—essential for companies with domain-specific language or branding requirements. Future versions will make it easier to apply these configurations site-wide, likely rolling out alongside Content Studio 6.
Enonic currently uses Gemini 2.0 in production, but plans to move to Gemini 2.5 once it exits beta. The improvements are notable, especially in reasoning and structured generation tasks.
As one attendee asked about tailoring AI behavior by user context—such as writing in different tones depending on the content area—Mikita confirmed it’s already possible, and further improvements are in the pipeline to support even more fine-grained control.
Want to try Juke in your own environment or learn more about the tech behind it? Reach out to the Enonic team today.