How to Build a Search Solution on Explorer 4.0
Dive into the newest version of our enterprise search solution Explorer.
Written by Thomas Sigdestad on
We recently held a Meetup where our Senior Software Engineer Christian Westgaard demonstrated how to build a search solution on our enterprise search platform Explorer, which is currently in its fourth iteration.
In this companion blog post, we delve into a practical application of Enonic and the Explorer tool, demonstrating how to efficiently manage and search data, specifically focusing on a car dataset from Finn.no.
Watch the video:
The Role of Explorer
Explorer serves two main functions: Indexing data in a structured manner to facilitate advanced searches. In this demonstration, we’ll mainly use Explorer to perform a useful task. To create a searchable database of cars.
Setting Up Enonic and Explorer
The process begins with setting up Enonic. After creating a sandbox and installing Explorer directly from the Market, we’re ready to use this powerful tool.
Creating a Document Type and Collection
The first step involves defining what data we will store and search. In this case, it’s cars. Christian has created a document type in Norwegian, allowing for automatic field generation, which we’ll explore later.
Alongside this, a collection is set up to store the data, essentially a standard XP repository named “Biler” (“Cars”). This setup is crucial for the data indexing and retrieval process.
Populating Data through REST API
There are two methods to populate data: building a collector within Enonic or using an external script to push data via a REST API. For this demo, we have chosen the latter, which necessitates setting up an API key for security.
The REST API endpoint is versatile, supporting various operations such as CRUD for bulk and single entries.
Writing a Crawler and Fetching Data
Christian developed a crawler using Node modules, particularly ’Surgeon’, which parses HTML into DOM structures and allows CSS selections within these structures. This crawler fetches car data from Finn.no, capturing detailed information like links, car attributes, and more.
To run this crawler, Christian used ’bun’, a project aimed at resolving common JavaScript issues, serving as a faster alternative to Node and NPM. As the script runs, it fetches car data from Finn.no, which is then reflected in the Explorer’s growing car collection.
Utilizing Data in Explorer
Explorer automatically generates fields in the document type based on the ingested data, categorizing them as strings, numbers, dates, etc. This capability is essential for displaying information on a web page and searching through the data.
Creating an Interface for Searching
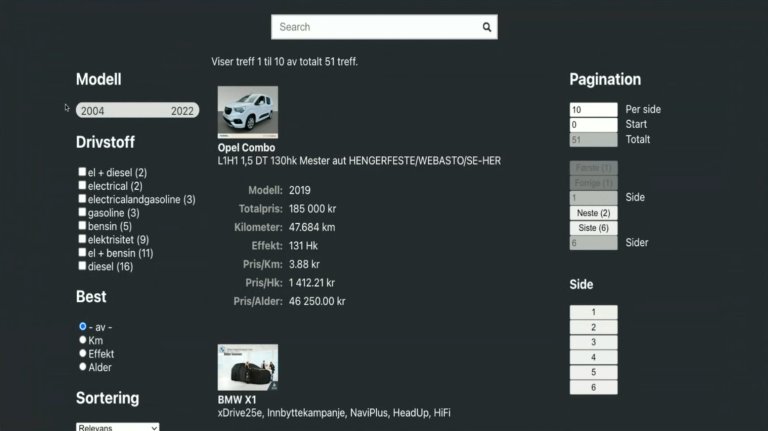
To search the data, an interface is created in Explorer. This interface allows for boosting certain fields, enhancing their weight in search results. Using GraphQL, we can execute searches, aggregate and filter results based on various parameters like car models, age, and fuel type.
Building a Search Client with GraphQL API
The search client, built with a simple create-react-app, leverages the GraphQL API for its functionality. This API supports features like highlighting, filters, and aggregations, allowing for refined searches based on specific criteria.
Enhancing Search Capability
After adding the interface to the API key, we can further refine the search functionality. For instance, we can sort cars based on price per kilometer or filter by fuel type. Aggregations are used to determine the range of car ages and types of fuel available.
Pagination and Advanced Filtering
The search client also incorporates pagination, using GraphQL to specify the number of results per page and the starting point for each page. It can also be used to create a “Load more” results button.
Finally, the client supports advanced filtering. These features add a layer of convenience and efficiency to the user experience.
Exploring the Benefits of Explorer in Enonic
Explorer extends the search capabilities of the Enonic platform beyond its internal data, allowing for highly customizable searches. This adaptability is particularly beneficial for aggregating and searching various data types, as demonstrated in the Helsebiblioteket public site example, which aggregates content from 50–70 diverse sources.
In conclusion, the integration of Enonic with Explorer offers a robust solution for managing and searching diverse datasets. Whether it’s for aggregating data from multiple sources or enhancing search functionality, this combination proves to be a powerful tool in data management and retrieval.
Check out Explorer on Enonic Market.